前言
之前写了一篇对于0代码基础的我来说,我是怎么用AI来做出自己自用的一些小玩意的思路,没看过的可以看看这篇。
之前开始研究opencode之后,逐渐熟悉了这种多Agent分配不同任务的模式。除了opencode和omo更新格外的频繁经常要去看文档重新配配置以外,我觉得整体还是非常舒服的。
这几天因为有一场我很想抢到票的演唱会,但是抢票网站每次濒临开抢之前都会触发cloudflare的等待盾,进去了之后就发现库存已经没了。

和过来人朋友聊了一下得知,这种日本的一般发售一般都是脚本大战,加上肉身在中的原因,所以不要指望手抢能抢到。
我一听那就来劲了,可不可以写一个脚本,放到日本的机房上,然后到点了自动抢票呢?而且刚好有以下的原因,使得用AI vibe一个这样的抢票脚本难度并不是很大:
- 抢票全程只需要用浏览器,抓包可以直接F12看浏览器请求
- 唯一的验证是谷歌的reCAPTCHA,这个有很多很便宜的在线验证解决方案
- Chrome devtools MCP最新的版本支持使用已经打开的Chrome窗口,不需要新开重新登录。
于是,开干
准备工作
1.1 和AI对话,聊需求,出设计文档
聊需求,让AI明确需要做什么功能,用到什么语言和技术栈,这一步是必不可少的。按照我们顶部的文章中所说,只需要大概给一个你想做的功能/方向,剩下的全都让AI来给你提问题,你进行回答就行。
因为gpt和claude在这方面比较敏感,所以选择和gemini开始聊。我直接说,我需要做一个抢票脚本,抢票平台是asobi ticket,目前暂定是使用python写,要有一个webui。现在你需要给我一个初步的开发文档。但是不要着急,在输出最终的文档前,我还需要补充哪些信息?在我回答完所有的问题之前,不要给我最终的答案。
在这最开始这一步中,我只有一个大概的思路,但依旧遵循了“让AI持续提问到没有问题可问”的原则。另外,gemini 3的知识库很广,所以我直接说是xx抢票平台,它知识库里有的话我就不需要自己进一步描述了。
之后就是一步步回答问题,AI大概会说,这个平台大概率会有什么什么样的验证机制,抢票的各种接口怎么获取,要用模拟点击(playwright)还是纯API…中间肯定会碰到自己不懂的术语,那么让AI解释一下并给出几个方案,并说明优缺点就行了。
聊完之后,便得到一个开发文档。当然这只是初步,印象中最初我这版只确定了要用python写脚本,然后网页是flask,另外登录的时候采用bearer token,抢票纯API,人机验证走2captcha,自己手动点击兜底这几个要素。其他的todo和技术栈都是AI自己生成的。

事实上,rust只是我脑门一热就给他这么说了,实际对我来说肯定还是Python更好上手一些
1.2 必不可少的Chrome devtools MCP
因为我是小白,所以我不太能看得懂网络标签页中的各种请求,但是playwright可以很好的帮我拍解决这一点。然而playwright存在一个问题,每次都是新开的浏览器窗口,不会复用我自己在用的Chrome窗口。好在在最新版本的chrome中,chrome devtools MCP解决了这个问题。
https://developer.chrome.com/blog/new-in-devtools-144?hl=zh_cn#devtools_mcp_server_updates
先把自己浏览器的开关打开了
开发者必须先前往
chrome://inspect#remote-debugging明确启用此功能。
然后在opencode的MCP配置文件中配置以下内容即可
"mcp": {
"chrome-devtools": {
"command": [
"npx",
"-y",
"chrome-devtools-mcp@latest",
"--autoConnect"
],
"type": "local"
}
}然后运行一次opencode看看MCP有没有正常连接上就行。因为omo内置了playwright,所以有的时候抓包的时候需要在提示词中显式调用chrome-devtools代替playwright
搞定了开发文档和框架,以及装上了必备的MCP之后,差不多我们就可以进入cli的部分了。
开始编写
2.1 利用普罗米修斯(Plan)进行计划
因为我们当前的开发文档其实还是比较简陋,只是大概标注了需要实现的功能和技术栈,而具体怎么来实现——作为小白的我来说其实并不好说明白。但是如果有现成的问题和选项可以让我选择,那就很直观了。
在omo前几天更新到了3.0.x版本之后,现在一共有三个主要的代理:西西弗斯、普罗米修斯、Atlas。西西弗斯一般的任务直接做就行,而普罗米修斯其实就是cc的plan mode,非常适合从零开始做原型或者加重大功能,需要拆解成小块小块的任务的情况。而且现在的plan mode也比之前更智能了,会自动提供对应的选项进行选择,这点倒是对齐CC了。
当前omo还有更加细分的子代理,比如有的子代理会对普罗米修斯生成的计划进行审核,查看是否有缺漏的地方(metis);还有的子代理会对生成的计划进行质量和安全评估(momus)。他们3.0版本的这一套Planner花费时间给我的感觉首先就是花费的时间之久,但是实际上确实效果很不错。比如普罗米修斯我设置的就是opus模型来做计划,metis和momus则是交给gpt系列,因为众所周知gpt一般都是慢工出细活且适合debug。
如果你想要进一步了解各个子代理的设置,可以参考官方文档。
最后相关的计划文件会交到.sisyphus这个文件夹中,避免了到处在目录里乱拉文档的情况。
2.2 计划完成,Atlas负责调配任务,开始编写
Atlas这个也是3.0版本出的新代理。它不写代码,而是分配给不同的代理不同的任务:该写后端的去写后端,该写前端的去写前端,需要搜集资料的就去专门搜集资料。什么模型该干什么事情其实一定程度上可以缓解逮着一个模型可劲蹬消耗过大的问题;另外我其实个人非常喜欢gpt-5.2,但是前端它确实没办法,oh-my-opencode这个什么模型干什么事情的工作流就非常舒服。
当然,前提是你一定要配置好对应的模型,opencode一直因为配置繁琐而被诟病,好在当前有很多软件都已经支持了用图形化的方式进行配置,这里就推荐两个:
优先推荐ai-toolbox,对比cc-switch可配置omo
https://github.com/coulsontl/ai-toolbox
https://github.com/farion1231/cc-switch
我的个人配置分享,仅供参考
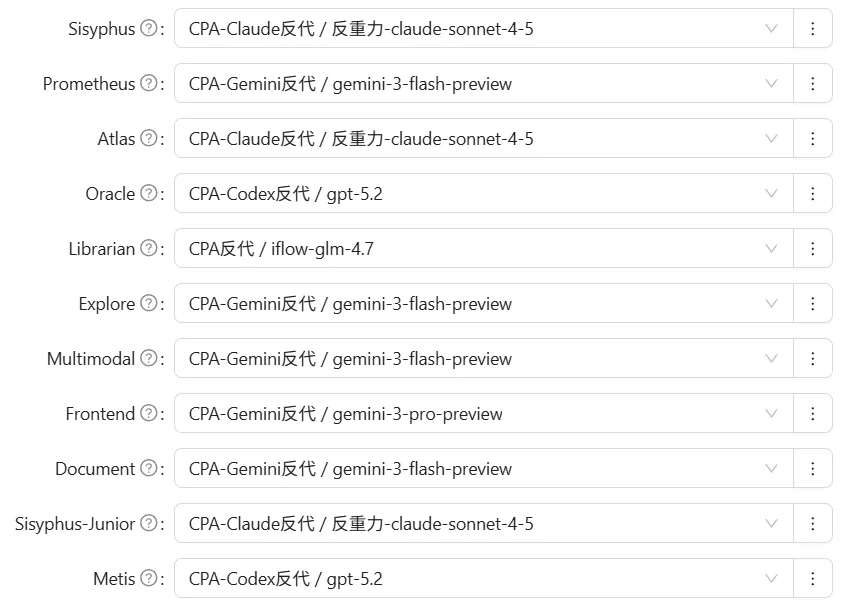
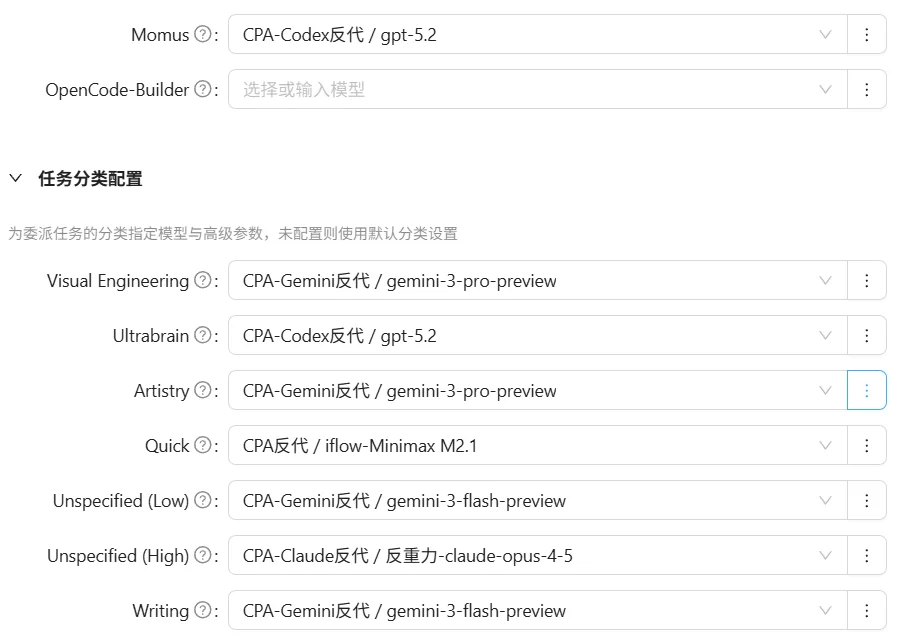
当然这么配置完了还是不够的,我们的模型当前还“不够聪明”,这是因为我们没有配置options参数导致的,详细的可以看这篇文章。
https://linux.do/t/topic/1497563
官方文档相关的链接:https://opencode.ai/docs/models/#configure-models
个人的碎碎念:如果你只使用Claue/GPT/Gemini,那么直接照抄上面的帖子就够了。如果你用了glm/minimax/deepseek等模型,看看有没有兼容其他SDK接口的版本,对着官方文档看支持什么参数,openai-compatible的话我是没有配的。
反复调试
Atlas的强度很高,干一个活的时间用时真的挺久的,建议是干活开始你就可以开始处理别的事情时不时回来看一眼了。我大致放着没管,中途确认了几次浏览器调用chrome devtools的权限之后,大概一个小时多就完成了一个初步的webui+python脚本。其实这样做不太好,应该前后端分步完成,一把梭不太好,但是考虑到计划文档中写了可能AI也就一起规划了这么做了。
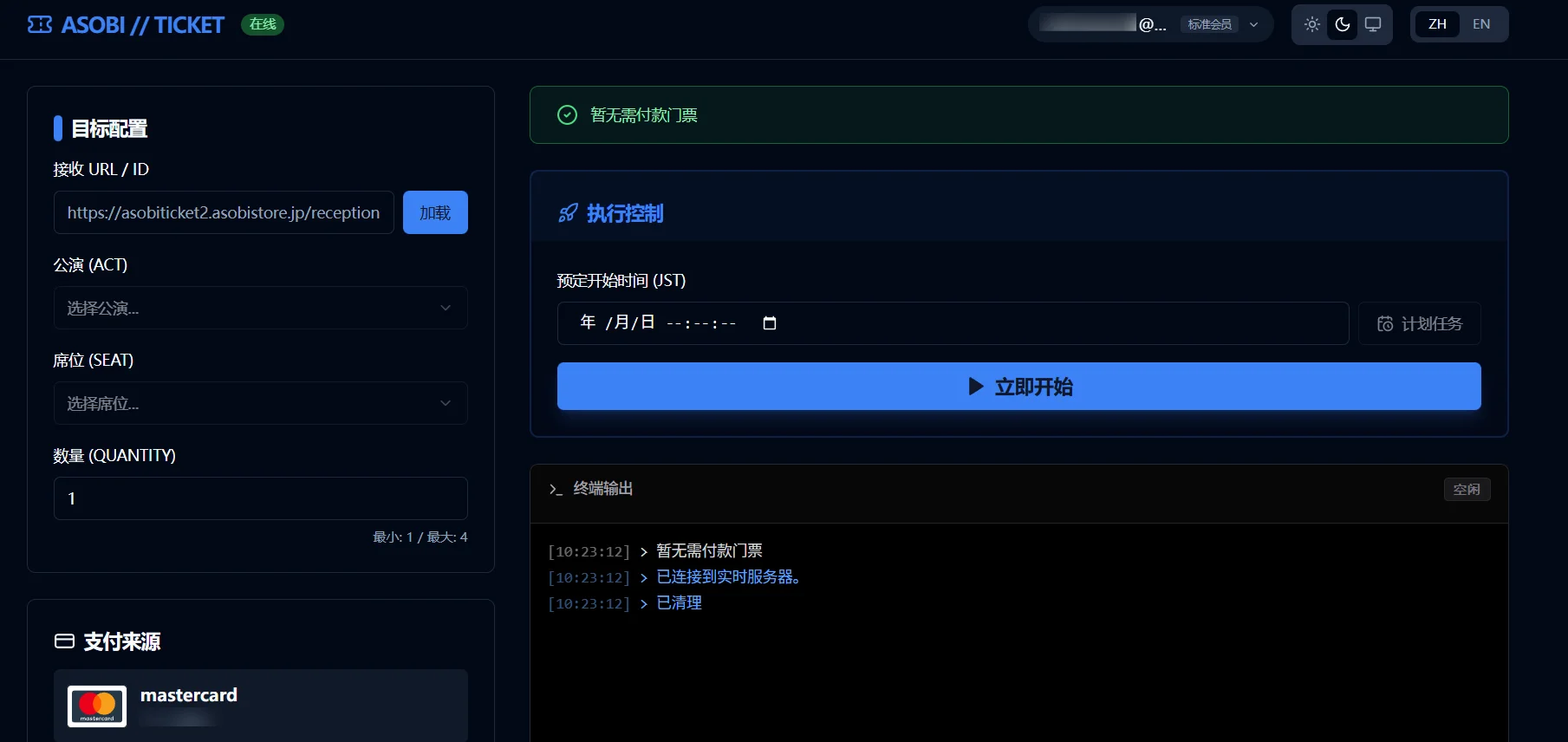
事实上,截图中并不是最初的版本。最初的版本漏洞百出,但这不要紧,一开始的版本肯定是不能让你满意的,这也就是我们接下来说的一步步调试。
经过总结,我个人的经验是如下几点:
- 详细的描述问题:什么情况触发的?具体问题怎么表现?预期应当是什么表现?有没有感觉可行的解决办法?
- 让AI创建对于此问题创建更详细的日志,重新运行,粘贴对应的日志,它自己会想办法弄明白的。
- 不要囫囵吞枣,一次只解决一个问题——哪怕你在运行过程中发现了别的问题。记下来,解决了现在的等会再说。
以下是我这个项目中遇到的问题和我的调试解决办法,因为是具体例子,可能需要你抽象浓缩成自己的总结。
3.1 登录问题
AI尝试解决的第一步是登录。一开始它使用的方案是playwright模拟点击进行登录。这种方法确实可以,但是问题是登录过的账号重新再用一次这种登录实在是太慢了。于是我和AI说:
“当前,webui登录使用的是playwright方案,过去登录过的账号也使用这种方式,导致每次登录账号花费很长时间。是否存在其他的登录方案,如使用token/cookie,对过去登录过的账号进行保存,在后续登录的时候快速登录?”
你看,这便遵循了我们上面提到的原则:
什么情况触发的?具体问题怎么表现?预期应当是什么表现?有没有感觉可行的解决办法
印象中这个部分我是让Planner自己探索并帮我规划了一下,使用playwright之后它自己发现网站使用的是bearer Token,那么只需要在第一次登录的时候保存,后续直接复用就行了。后续我指出是否存在token过期失效的问题,它又自己规划了一下加上了fallback到playwright登录作为保底的方案,至此,登录的问题就解决了。
3.2 获取公演信息的接口问题
这一个部分大概是花费我时间最长的一章。因为该网站的可分为抽选、抢票两种情况,但是这两种情况的接口其实是一样的。
3.2.1 对会员状态不同的检验
然而在抽选中,存在对“大会员”状态的校验,你可以理解成FC的形式,有些活动的抽选是只有大会员才可以参与的。
因此,依旧是交给AI:
“当前有些活动需要校验用户身份是否为高级会员才可以参加抽选,请你使用chrom-devtools,尝试申请这个仅高级会员才允许参加的抽选链接:这里放一个参考链接,从请求中找出校验的用户信息参数。要求在解析抽选链接后,若识别到是高级会员专属,核对账号信息,若不符合直接拒绝进行下一步,并输出相关的日志,且在webui中提醒。”
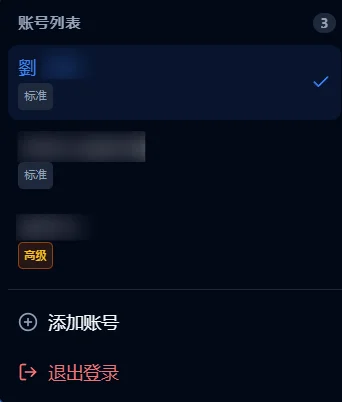
AI一次就找到了校验的参数,这个时候我突然想到,那是不是可以在登录后就获取用户的会员信息,并且在顶栏中可以明确表明账号信息,这样使用起来更加直观?于是继续给AI提要求,要求把获取用户会员信息这一步骤放到了登录后,且在webui中放一个徽章用于展示会员信息。
3.2.2 对支付方式进行选择
AI在第一版的计划中已经自行抓取到了使用信用卡支付的方式是什么参数——但是问题是只写了信用卡支付!实际上还有其他便利店的支付方式——711、罗森、全家……等等。这一部分依旧是交给AI,给他一个浏览器和示例链接,在选择支付方式的页面让它进行点击并抓取请求,然后就可以自己获取到其他支付方式的API,再让它做个选择的方式就好了。
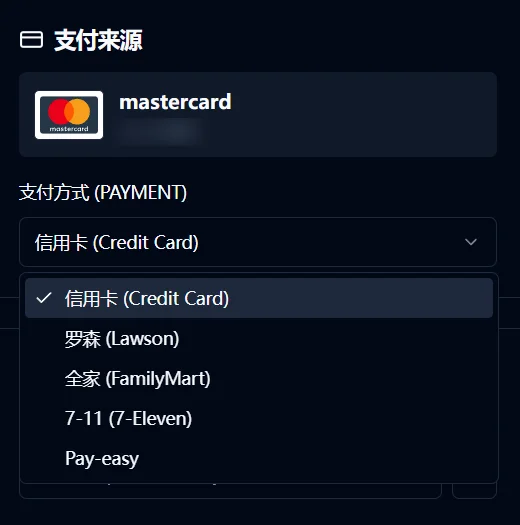
然而,在实际测试中,我突然意识到有些活动支持的支付方式不一样。有的只能信用卡,有的活动部分便利店不支持。虽然说用户可以自己提前查看好活动详情确认支付方式,但是在脚本中没有对应的报错和fallback会很奇怪,于是再次给AI描述我遇到的这种情况,然后它自己加了一个解析链接的时候自动解析支持的支付方式,若不支持的话自动fallback到可用的支付方式进行申请,并在日志中提醒用户。
另外善用github的issue功能,想到了问题就及时记录放在这里,可以后面再来一个个解决。详情可以看我最开始提到的我自己的帖子。
3.3 谷歌人机验证的解决
在我自己实际申请的时候,发现会触发谷歌reCAPTCHA v3验证,也就是那个会让你选出图片中所有xx物品的图片。这个人机验证我每次自己过都要点半天,压根不能一次就过。GPT和Claude在我要求搜索是否有云端验证方案的时候都明确拒绝了我,没想到Gemini一通搜索吹后找到了解决的办法。它告诉我可以尝试2Captcha这种付费的验证方法(无广告,且我自己实际测试之后感觉验证速度也就那样)那么就让AI获取官方的文档,给脚本加上云端验证的功能,若失败了则在本地调起浏览器进行手动的验证。
反正这一个部分还需要打磨。因为我在实际的抢票的过程中再次触发了cf的等待盾,但是脚本依旧可以走到获取公演场次并创建订单调起人机验证的部分,就是因为人机验证的部分打开的页面也是cf等待盾,我手动验证还没过完就给我弹出去了。而等待盾不触发的时候暂时还没这个毛病……我暂时还没想到怎么调试,可能要等到下一次抢票人多触发的时候再重新让AI帮我看下请求来解决了。
3.4 考虑边缘情况,增强脚本鲁棒性
TL;DR:在开发中需要完善业务逻辑覆盖,提高项目的健壮性。
在我实际使用中,发现了更多需要完善的逻辑上的疏漏:
- 在库存不足的时候,脚本没有直接停止而是继续重试
- 在抽选日期还没有开始的时候,脚本没有直接停止而是继续重试
- 以及更多的现在还没有测试出来的bug
也就是说,需要你自己来考虑更多的边缘情况,并且加对应的代码来进行应对,G指导对此的总结是

而这种思路也被称为防御性编程,以下来源于维基百科。
防御性编程(Defensive programming)是防御式设计的一种具体体现,它是为了保证,对程序的不可预见的使用,不会造成程序功能上的损坏。它可以被看作是为了减少或消除墨菲定律效力的想法。防御式编程主要用于可能被滥用,恶作剧或无意地造成灾难性影响的程序上。
主要概念:若例程收到错误的资料,即便错误资料是由其他例程出错所造成,此例程也不会受到伤害。
防御性编程通常通过以下途径,从而提高软件和源码的质量:
- 提高工程质量——减少bug和问题
- 提高源码可读性—— 源码应该变得可读且可理解,并且能经受代码审计。
- 让软件能通过预期的行为来处理不可预期的用户操作。
值得注意的是,过度的防御性编程可能会预防不可能会发生的错误,这样将导致运行时间与维护的损耗。当源码中拥有过多异常捕捉和异常处理,这有可能导致结果不正确或者被隐藏。
而我采用的则是试错法,在实际的测试中遇到特殊的问题(刚才提到的库存不足、日期未到)则对代码进行查缺补漏,这样可以避免AI过多考虑,进行过度的防御性编程,考虑过多不存在的错误导致代码越来越屎山。

脚本 -> 产品
在完成了基本的功能开发、测试增强鲁棒性之后,这个脚本的核心功能:抢票——已经是处于一个可用的功能了。但是在实际使用的时候,你肯定还会有更多不满的地方(痛点)
对于我这个项目来说,我感觉只能给一个账号抢票,不能多开很不爽,这就是我发现了一个痛点;另外既然我都有多个账号了,能不能做一个仪表盘,一键查看当前我所有账号有哪些需要付款哪些中选?这又是一个痛点。
在实际的开发过程中,这种思考的过程叫做需求建模。你已经解决了你的核心需求(抢票),现在需要做的是增量需求(多账号支持、订单状态监控)
其实这个时候的逻辑,就要从写代码的逻辑切换成产品经理的逻辑。产品经理需要有以下的职责:
- 需求发现:也就是我们刚才找到实际使用中的痛点。你需要考虑到使用过程中你的需求。
- 产品设计和定义:你需要将你刚才发现的痛点,思考出一个合适的解决方案。比如我刚才提到的多账号管理,这个多账号管理具体需要是一个怎么样的页面?点击查询之后该按什么顺序去轮询API?
- 优先级管理:有的时候你可能会想到很多想做的功能,但是PM需要做的事情包含了给工作排序。你的时间和精力是有限的,所以你需要有一个优先级。对我来说,多账号同时抢票实现的难度更大,可能还要上指纹或者代理池;而多账号管理查询则难度不大,而且能显著提高我的使用体验,那么我决定优先做这个。
- 协调与沟通:在公司中你要对接程序员、市场balabala一堆人,这个时候就需要你协调你多方。作为个人开发者且做的是小玩具,这种情况其实比较少,很多时候你担任了所有的职责。对于大部分小白来说,其实主要担当的就是PM的责任。代码?让AI实现。测试?自己测试+AI debug。市场?其实也就是分享出去,看看大家反馈的情况再进一步优化
- 生命周期管理:其实就是你这个产品从上线到下线的整个过程。主要可以分为引入期、成长期、成熟期、衰退期、转型或下线这5个阶段。
对于我这个脚本来说,引入期就是最基本的抢票逻辑,这个时候我不用考虑别的,就看最正常的情况下我的脚本能不能抢到一张票;
成长期则是当前我处于的时期,这个时期我发现了各种各样的痛点,如多账号管理和待支付订单检验;
成熟期的话,则是从“加功能”转向“保稳定”。这个时候你觉得没有什么功能需要加了,则需要考虑产品的稳定,如怎么样降低抢票中触发人机验证的概率,在多账号同时抢票的时候如何降低失败率;
衰退期,对于这个例子来说,假设未来官方把抢票改成了App的形式,并且上了复杂的加解密;或者说抢票不再存在,而是全部改成抽选,那么我的这个脚本就没用了。接下来我们需要考虑的就是转型或者下线。
转型or下线:若抢票失效了,但是多账号管理的功能还管用,我是不是可以把这个脚本做成一个专门管理账号的产品?比如自动查询当选情况,注册机自动申请抽选等等;如果真的无懈可击或者不想做了,那么仓库存档,代码停止维护。
一些杂项,主要是开发中的踩坑
这一部分很杂,但是还是尽量总结了一下:
TL;DR:模块化设计,避免代码耦合;适时简化代码,避免技术债;该引入组件就引入组件,别让AI瞎写
- 因为一开始只考虑做了抢票部分的功能,所以在一开始代码就是比较简单的。但是后续如果要加功能的话(如多账号管理、登录信息加密保存)这个时候就要注重模块化的设计,避免代码耦合,影响后续的维护。当前AI如果不强调,真的很容易在如
App.tsx这种一个文件中写上上千行的代码而不进行拆分。 - 因为一开始代码只是一个“能跑”的程度,如果一味的加新功能,有的时候旧的模块还没完善好就加新功能,最后回过头来发现项目已经成了屎山。所以在完成了一个或若干个功能之后,要停下来进行code review,保持代码的健壮性。
- 在做webui的时候,我发现gemini很喜欢自己写组件元素,哪怕是在我已经使用了tailwind和shadcn/ui的情况下。这个时候就需要在
AGENTS.MD里面写好要求,或者加入对应的skills。
另外今天刷到了一个别的帖子,其他佬友的思路很不错,适合小白从零开始vibe。
https://linux.do/t/topic/1517203/61?u=sallyn
https://linux.do/t/topic/1517203/109?u=sallyn
https://linux.do/t/topic/1517203/29?u=sallyn
写在最后
以上就是vibe这个抢票脚本(虽然现在已经从MVP正在转向产品了)的一些经验,依旧抛砖引玉。
或许后续vibe部分的博客写多了可以做个主贴把相关的都放到主题里整合一下