前言
最近其实在研究有没有半自动或者全自动的烤肉1流程。之前大家可能都知道 OpenAI 有一个开源的模型 Whisper 以及相关的一些延伸项目。在B站其实你可以看到很多这种烤肉的项目基本上底子就是 Whisper 来的。
放几个 Whisper 的链接,感兴趣的可以自己去看,但是不是我们这篇文章要讲的重点
但是这东西其实已经过去蛮久了的,论准确度其实已经比不过新出的如 Qwen3-ASR 或者 微软的 VibeVoice 了。
在我薅 ElevenLabs 这个模型之前,我是用的 Qwen3-ASR 的,但是问题也很明显:
- 不像 Whisper 那样原生带轴,需要拆分语音成小块间接实现,效果不好
- 转录的时候会莫名其妙出现开始反复重复一个词然后后面整个崩完的情况
至于 Gemini 有的人说多模态很不错,但是实际测试的时候不知道是不是因为没有一个单独的 ASR API,很多时候转着转着就漏句子了,然后给你的 SRT 是有幻觉的,时轴完全对不上。
然后 MIMO 那个 ASR 模型出了,我在X上刷到一篇说小米这个模型中文转录是当前第一的模型,作者还给了另外一些模型的榜,Scribe V2 这个模型就在第二的位置。
于是我好奇去搜了一下这个我之前不清楚的模型,在 Artificial Analysis 这个站上的错误率居然是最低的!
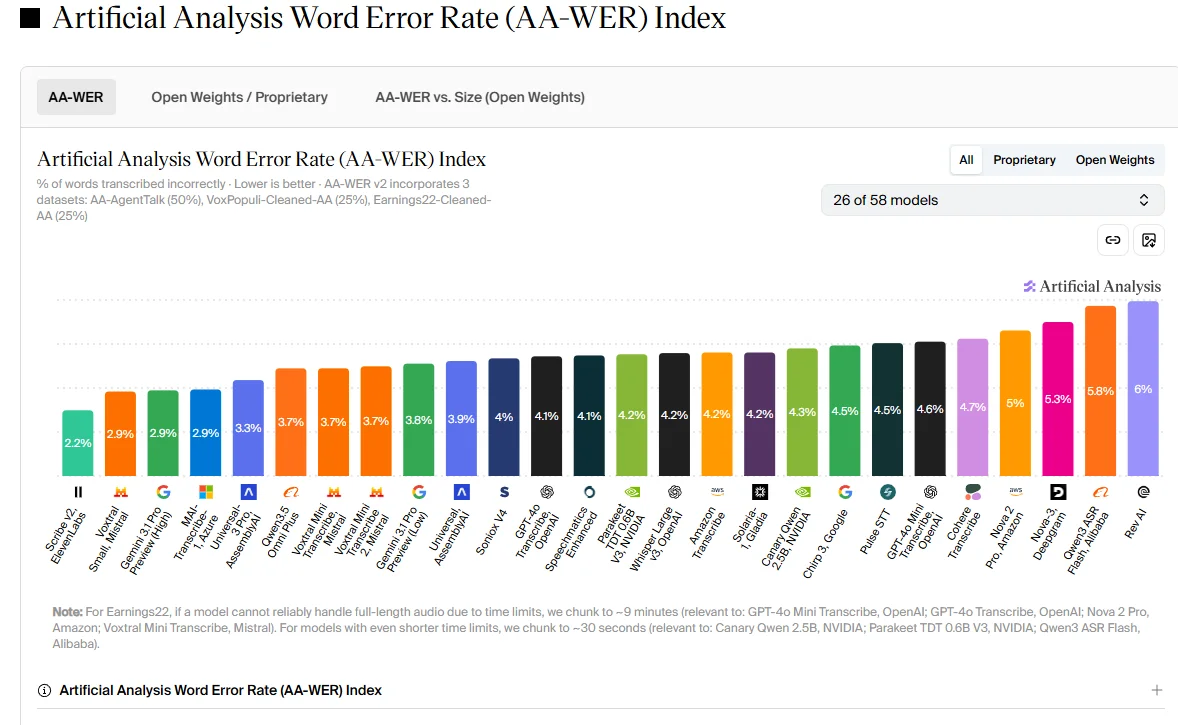
什么概念呢,2.2%大概是 100 个字转错 2 个字的水平。
另外让我们看看价格吧,越往左下,效果越好,价格越便宜。
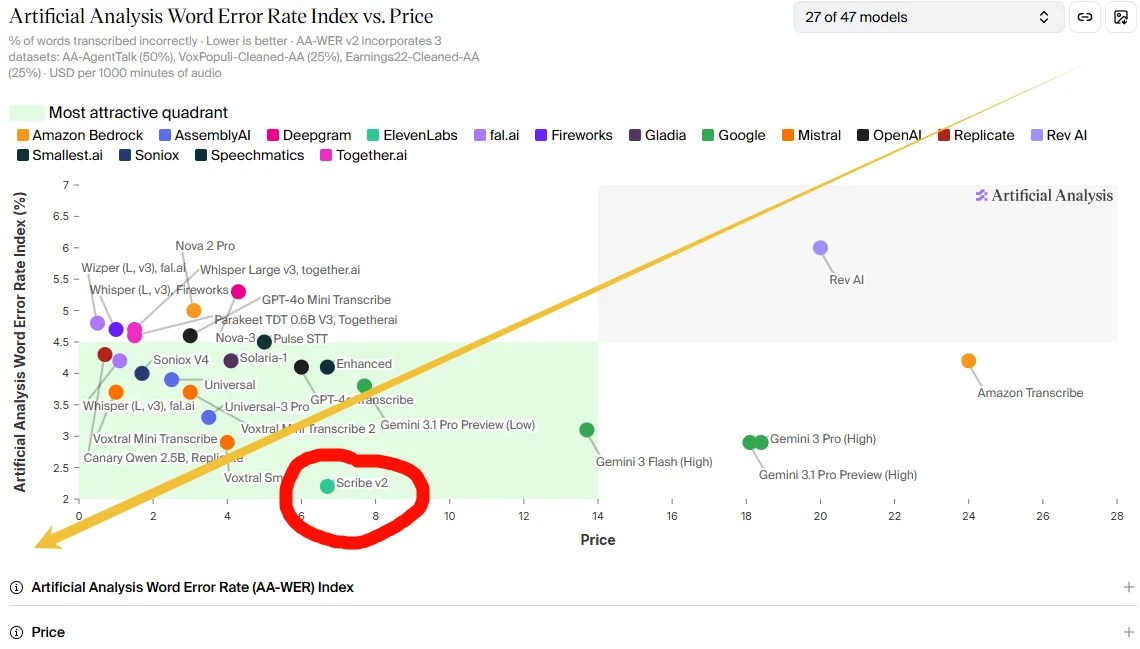
可以看到这个东西在和 OpenAI 旧的模型差不多价格的同时,错误率大大降低了。
怎么用
那有的朋友就要说了,这么牛逼的模型怎么用呢?我看了一下,ElevenLabs 的网页版免费层级就有这个模型的使用权,不过是按照点数计费的。
一个免费账号有1w点数,大概可以转录 9m30s ~ 10min 的视频刚好。所以如果你的视频很长,可能需要你拆分成差不多的长度,分次翻译。
如果你能找出来一个切分音频比较好的算法(我看很多声音克隆或者TTS项目都会有一个内嵌的音频切分的功能)然后想办法把网页版这个上传的接口搞出来,那么配合注册机就可以 自动切分音频+自动注册账号+一个账号转录一个切片+批量下载转录好的SRT……
注册账号也很简单,邮箱注册就行。不需要手机接码、不限制域名邮箱(至少我的.top是能够注册上的)也就是说,你有能力完全可以造个注册机出来。
也就是说你完全可以去什么阿里、火山、spaceship花个十来块钱买个一年的.top域名,然后用站内的这个教程:https://linux.do/t/topic/1666961 去搭好自己的临时邮箱,然后库库用就完事了。
但是我确实不知道怎么造注册机,GPT和Claude没有办法从零开始干,DS-V4-Pro 给我用的是纯 Playwright 方案,但是一个流程都没办法跑通。
实际的效果非常的 amazing 啊,我转录的基本上是中/日/英的音频,有一些小问题(我会在下面的板块讲)但是总体来说已经不需要大改了,而且官网还有拼写检查的功能,可以消除掉一部分因为转录造成的错误。我已经用这个模型完成了一个差不多一小时日语单人节目的熟肉了。
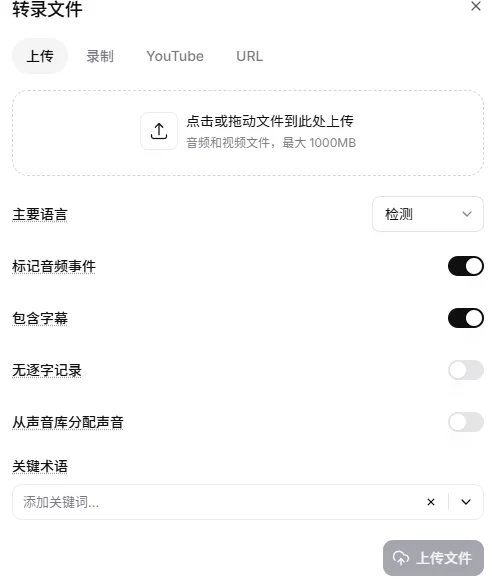
另外给大伙看一下这个网页有的功能吧,你要能抓到接口直接纯命令行完成这个过程我觉得应该不是难事,做个反代版的webui应该也可以。
- 标记音频内容:会标注像(笑声)(脚步声)这样的内容,用过油管的应该懂
- 包含字幕:一定要打开,不然就是纯转录了。
- 无逐字记录:有的时候人说话是会口胡的,这个等于帮你做个处理,我一般不开,交给AI
- 从声音库分配声音:没太懂,一般不用。
- 关键术语:热词,你觉得你这视频里有什么特殊名词转录容易听错的你就输进去。我一般输人名、模型名字、公司名字这些。
存在的问题
其实基本上也是转录模型的通病了。
- 多人节目可用性较差:老问题了,如果同时有多个人说话的,效果不好,现在我也没看到做多说话人区分很好的模型。
- 时轴准确度问题:实际使用的时候发现这个SRT的轴不一定准,有的时候第一句话明明讲完了,轴却会往后延伸到第二句话开头的一部分。但是大家如果是做视频字幕,肯定也会自己手动校一遍的,我觉得问题不大。
- 人名等专有名词问题:如果你没添加热词,那么很有可能其中涉及到的一些人名会转录错误,我觉得不是很影响,反正校对的时候能校对出来的。
推荐流程
- 买个域名,搭个域名邮箱,批量注册账号。要是你能做个注册机的话可以做个注册机
- 切分音频到 9m30s~10m 一个账号就翻译一个音频。如果搭配注册机你还可以把这个上传音频、翻译、下载SRT的抓下包然后做成个 WebUI 全流程跑通。
- 写个 skill,可以告诉AI,这个字幕是音频转录的,让他先进行一次拼写检查。然后按照你平常做字幕的习惯,比如末尾标点符号不要、中间的单个不成对的标点符号替换成空格、两条字幕之间的间隔小于多少秒自动拼接等等……如此得到的字幕再进行最终的翻译,出成品。
- 导入进 ageisub/arctime/PR/剪映,校对、调样式、导出视频。
总结
这个模型的能力还是很强的。配合你自己写好的烤肉习惯、修正的skill,基本上在不校对的情况下出一个长视频的字幕还是很快的。
当然,有注册机和反代的话,省去注册账号和切分音频、换账号上传这些时间的话,更快。
Footnotes
-
其实就是翻译其他语言的视频 ↩