尝试从零开始做一个项目
这周刚好 gemini 3已经发布有一段时间了,虽然说在刚开始出来的时候我用来做了几道题和用 App 的 canva 功能做了一个前端展示,但是实际上我还并没有测试它的代码功能。
https://x.com/Google/status/1990924447402828120?s=20
这周有一天我发现 ai studio 里面有一个 build 功能,说一句话就可以创建一个完整的项目,可以使用 TypeScript 和 JavaScript 进行构建。本来是抱着试一试的想法,打算做一个集成了 AI 的 RSS 阅读器,于是就尝试性地在 ai studio 里输入了一句话,让他帮我创建一个 RSS 阅读器,没想到试了一下,意外的效果还可以。
然而到了后期,可能是因为上下文太长了,而且本身我是要求以 Docker 的形式运行的,而谷歌网页的 build 识别到了隐藏文件或者是 Dockerfile 的话,是会直接报错的。于是我不得不开始考虑使用命令行工具或者是 Cursor 以及 Windsurf 这样的 IDE 工具来进行下一步的修改。
在我实际使用的时候,虽然说谷歌的 Antigravity 对于限额来说确实是放的很宽,但是实际上 bug 太多并不好用;而亚马逊的 Kiro 说实话模型太少了,而且免费额度给的不是很足;至于 Cursor 这个东西实在是太贵了,根本用不起;我还尝试了一下字节跳动的 TRAE,说实话,改起来效果确实还不错,而且又有免费的额度,但是就是排队实在要等太久了,而且不知道是为什么用起来非常的卡。
最后在刷了论坛和看了一下闲鱼能获取账号的容易程度,最终还是选择了被 openai 收购的 windsurf。优点也很明显:免费的模型有很多,而且绑卡的话,会送100的积分可以使用高级模型。而且可以很明确的切换 chat 和 code 模式,保证你想和 AI 聊想法的时候不会突然给代码来上一刀。
就这么面向大语言模型编程了几天,我自认为做得还算不错了。于是我把代码公开上架了 github。
结果没有想到当天就爆了。
原来是因为 AI 写代码的时候,它不会自行审查安全问题。它只会审查这个项目跑不跑得起来。如果跑得起来,那它就会直接通过,没有问题;而我也没有经验,也不会利用别的模型进行二次确认。于是就导致了代码中有一个遍历攻击的漏洞,让其他的人可以利用这个漏洞直接访问我服务器上的所有文件。
因此当我刚把代码公开不久,有人就说已经给我的订阅源加上了一个莲之空的订阅。莲瘟真真的喜欢随地拉屎我说实话。
一开始我还没有看我自己的站,我以为是他自己 fork 了一份仓库然后部署的。直到我没事干的时候登上了我的网站,看了一下突然发现了多出来的一个订阅,我才意识到我的站确实是有安全漏洞的。
于是当天饭随便扒了两口,回来就开始检查究竟是哪里出了问题。同时改着改着 AI 甚至让我使用SSH才能够访问自己的订阅管理页面。后面我越想越气甚至还上了TOTP这种二步验证的加密方法。说实话已经偏离了原来的来解决这个问题的想法。
然而直到熄灯,我也没有想办法解决掉这个遍历攻击的漏洞。我只能先把 SSH 管理订阅源给开着,然后使用隧道的访问方式。结果到了晚上,我想打开管理一下我的订阅源的时候,突然发现我这个隧道访问的方式也出了问题。明明显示的是 localhost 的但是就是进不去。属于是折腾了半天把自己和小偷都给拦在了外面。
然而在晚上小蔡帮我 review 代码的时候发现了这个遍历攻击的问题,加上我使用服务器的时候很差的安全习惯,有些不应该给的权限反而给了,把这个问题进一步的放大。于是我紧急把这个服务的 docker 给停了,第二天起来在 IDE 里直接标注出来让 AI 好好讲讲它昨天写的什么够吧东西。
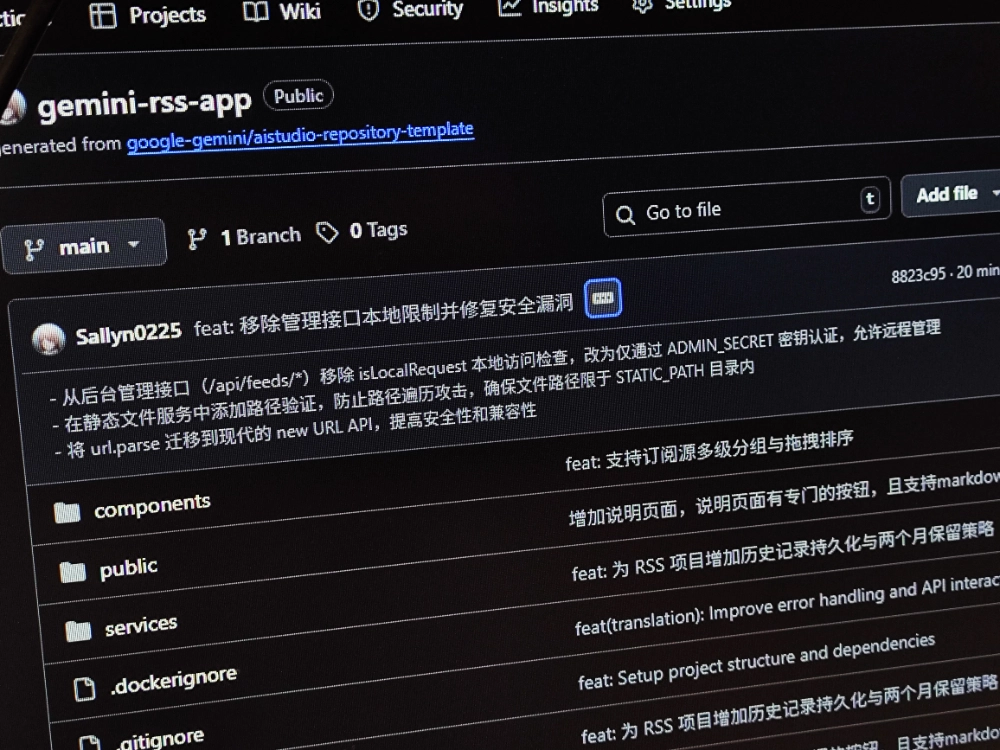
事实证明得益于 Gemini3,从零开始做一个项目确实不需要什么功夫。但是当需要完善项目以及后续的其他的运维/并发的时候,就来到了 AI 无法代替人做的部分。若是一个完全没有经验的人肯定会在这个地方犯错误。
所以这几天在小红书上看到有不少的人在想办法把自己生成的项目部署到服务器,甚至是部署到手机上。却没有想过自己做出的东西究竟会不会存在非常严重的 bug 或者问题。只能说 Vibe 开发的坑确实太深,不踩一次总是会有侥幸心理的。
虽然我已经尽力在完善这个项目,但是还是出现了很多我没有办法解决的问题。因为 RSSHub 只能获取到20条最新的 x 的消息,所以说我引入了一个 SQLite 数据库,可以做到消息的持久化存储。
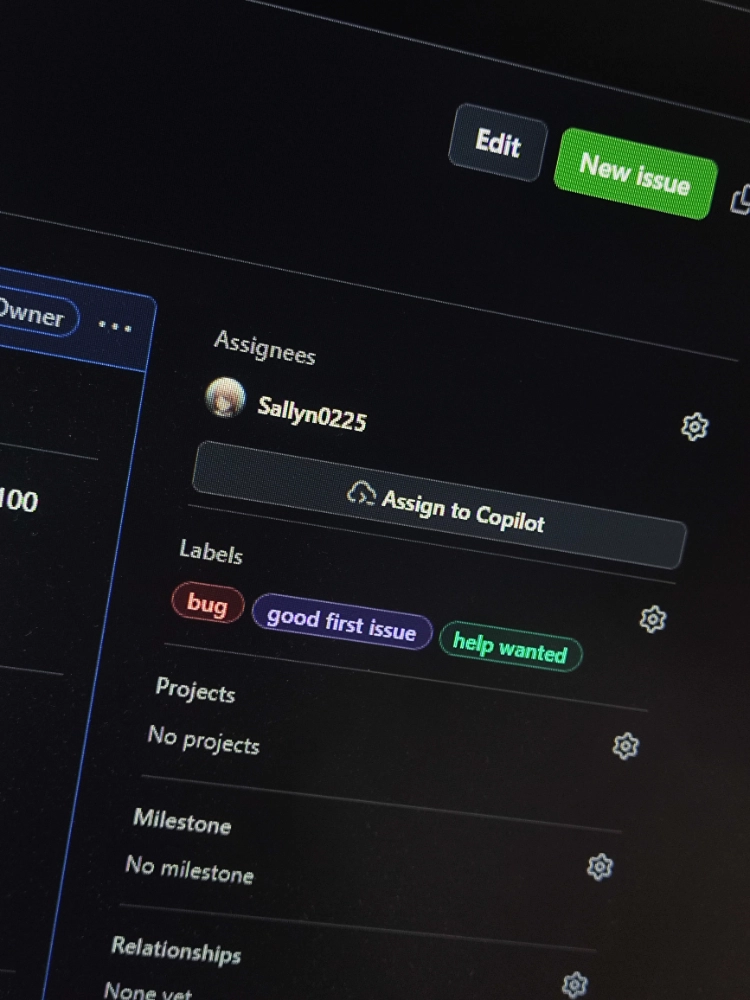
但是不知道是不是因为写合并消息的代码的时候出现了什么问题,现在消息库的最大上限是100条。也就是说只能存最新的100条消息。说实话这个代码影响的程度并不大,因为不太可能有人会查看100条以前的消息。但是这确实是一个 bug,而且我不知道怎么解决,于是我给自己提了一个 issue,并且打上了一个 help needed 的标签。这便成了我在 github 提交的第一个 issue。
我想估计这个 bug 修复了之后很长一段时间里我应该都不会进行维护了。毕竟是完全 AI 做出来的项目,虽然它确实实现了我需要的功能。但是里面有太多的我不清楚怎么实现的地方,所以我也说不准这个代码是不是真的可以用于生产环境。毕竟上一次的问题确实是几乎让所有人都可以访问到我服务器里的东西,这事给我留下了挺大的心理阴影。
或许 AI 写代码这一块完全代替人还有很长的路要走,但是对于实现基本功能来说它确实毫无压力。不得不让我一个明年就要出去找工作的人倒吸一口凉气,AI 都能干的工作,凭啥要把这个 hc 的位置继续留给你?我不由得这么想。