或许是最后的期末周了
上周总算是考完了我补考了三次的液压与气压传动,这周就轮到最后一门考试——自动机械设计了。
说实话,这门课我也是一节课也没去听,甚至连最后一节课画重点的时候我也没有去,当时印象中应该是在宿舍实在犯懒了就没有去。
于是,又开始了一年一度的速成环节。得益于AI技术的进步,今年我已经不局限于使用网页对话的AI,而是开始自己反代API,然后把API用于各种agent里。
另外,谷歌的notebooklm这个产品可以说做的确实是深得我心了。
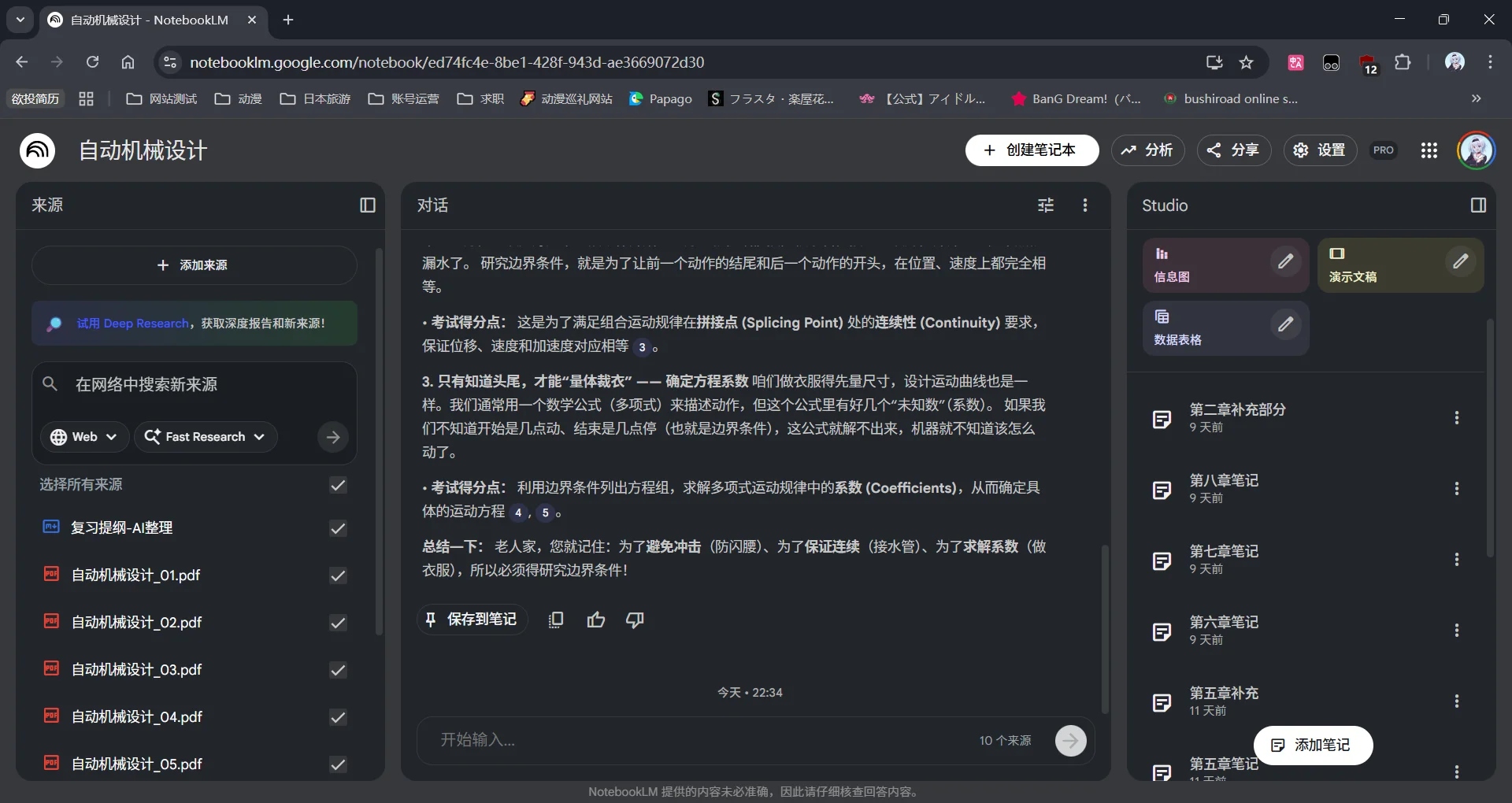
首先,左侧的部分是自己导入的资料部分。这个地方就是你原始的资料;中间的部分则是对话的窗口,在这里你的信息来源就是右侧的窗口,所以AI出现胡编乱造的概率会小的很多;在右侧就是你自己整理笔记以及notebooklm自带的一些复习小工具的地方,比如之前很火的AI播客和闪卡等等。
我首先先把老师的PPT转成了PDF导入到左侧的资料中,然后复习一张我就勾选一章的PDF,同时一直保持我已经整理好的那个复习重点的文件的勾选。这样可以保证AI的上下文不会有太大的压力,可以专注一章的复习。在对话中我让AI根据教材和重点复习内容找出知识点并且整理成即使是一个零基础的人也能看懂的水平,等到整理出了满意的版本就添加到右侧的笔记中。右侧的笔记又可以反过来添加到左侧的资料中。
notebooklm有一个不太好的地方,就是中间这个添加笔记,如果AI有两条消息那么就一定会被添加成两条笔记,没有办法合并。不过可以考虑把这两条笔记导入到左侧然后只勾选这两个,在对话窗口中要求AI进行合并,或许这是一个折中的办法。
在这么折腾之后,我们应该在右侧窗口中就可以得到各个章的笔记了。但是这个笔记肯定内容还是并不完全详细——毕竟还是受限于PPT转PDF,以及模型上下文,还有网页版AI降智的各种问题。这个时候我会带着原始的PPT和AI已经帮我整理好的各章的笔记,同时打开一个笔记软件(eg. 飞书、语雀)然后开始在PPT里搜索相关的关键词,如果AI已经整理的不错那我就直接复制;如果有疏漏就由我自己补充或者只是多看看相关的过程理解记忆。
这个过程中最主要用的还是随便一个AI对话工具,比如说kelivo, cherrystudio什么的,都行。读着读着有什么不懂的地方,就直接告诉AI:
我是一个80岁的老奶,现在我正在学习大学本科XX专业XX课程的教材内容。现在我需要你用我能够理解的方式,解释以下知识点然后就是进一步的追问,直到弄懂了位置。这种任务目前看上去还是gemini-3-flash-preview这种模型处理的比较好,到最后可以说:
好的,我已经明白了这个知识点。现在请你总结并规范用语/过程。假设在考试的时候遇到这类题目,需要简单明了的扣住得分点,写出规范的过程/使用规范的用于进行回答,现在开始给我生成答案。就这么做着做着,大概是弄懂了这门课的内容。虽然最后还是打了小抄。但是说实话,考完出来我发现我的亚洲提出似乎还是出了很大的问题,另外计算题我也有一道大题可以说是彻彻底底没有复习到。其他的几道大题虽然说是尽力写满了但是出来终究还是感觉有一股异味。
嘛,算了,都大四了,而且我还有平时分呢,这次只要45分就可以过了,其他部分我也写的挺多了,及格的话,应该是够了吧。
就是真的很害怕我重修的两门课程——机械优化设计、液压和气压传动不知道能不能顺利过关,如果不能过的话感觉可能就真的要进清考或者是延毕的斩杀线了。
使用minimax给老师交了PPT
之前看到有人说minimax的agent还不错,于是我去他们的网页版体验了一下。
结果确实不错啊,可能因为是海外版本的缘故,我让他搜索一下论文和专利也确实是会去谷歌搜索,而且引用的来源也是非常不错。另外做出来的PPT基本上也符合老师要求我们收集信息的要求。
可惜就是送的免费积分会过期,不过免费版本的agent做一些简单的任务看上去也是特别够用了。
其实一开始我是尝试用CC做的,但是不知道为什么CC的速度一直很慢,加上那几天他们开发团队似乎一直在拉屎,导致那几天我用的实在太难受了就没有用CC做完。
折腾了opencode
突然又刷到了另一个开源cli的爆火,看了一下居然仓库的stars和CC相差无几,但它是开源的啊。于是说干就干,在linux do搜索了一下相关的教程就开始折腾了。
https://linux.do/t/topic/1404993
不过说实话比起CC来说,opencode配置模型的过程只能说是极其繁琐:
- 在windows上运行并不会在对应的目录自动生成
config.json文件,还是需要自己手动创建一个。 - 配置文件不能使用cli工具或者图形化界面进行配置,只能对着json一个个改
- 配置渠道一开始需要自己手动一个个运行
opencode auth login然后输入API 密钥,对于渠道多的人来说很麻烦。
可能也是因为现在因为生态才刚刚建立起来吧,所以没有那么多优化的工具,加上他们发版也发的很勤快,所以即使有优化工具也要跟得上他们发版的速度,说实话也不是一件容易事。
在折腾的过程中,不得不说 oh my opencode 才是这个项目的灵魂。基本上安装上了这个就不用怎么再去自己折腾 opencode 了。内置了三个常用的MCP,另外还有一堆LSP服务。最主要的是一套自定义了的agents,负责后端架构的、负责前端设计的、负责阅读代码库的……这一套流程可以说是非常高效而且节省token。
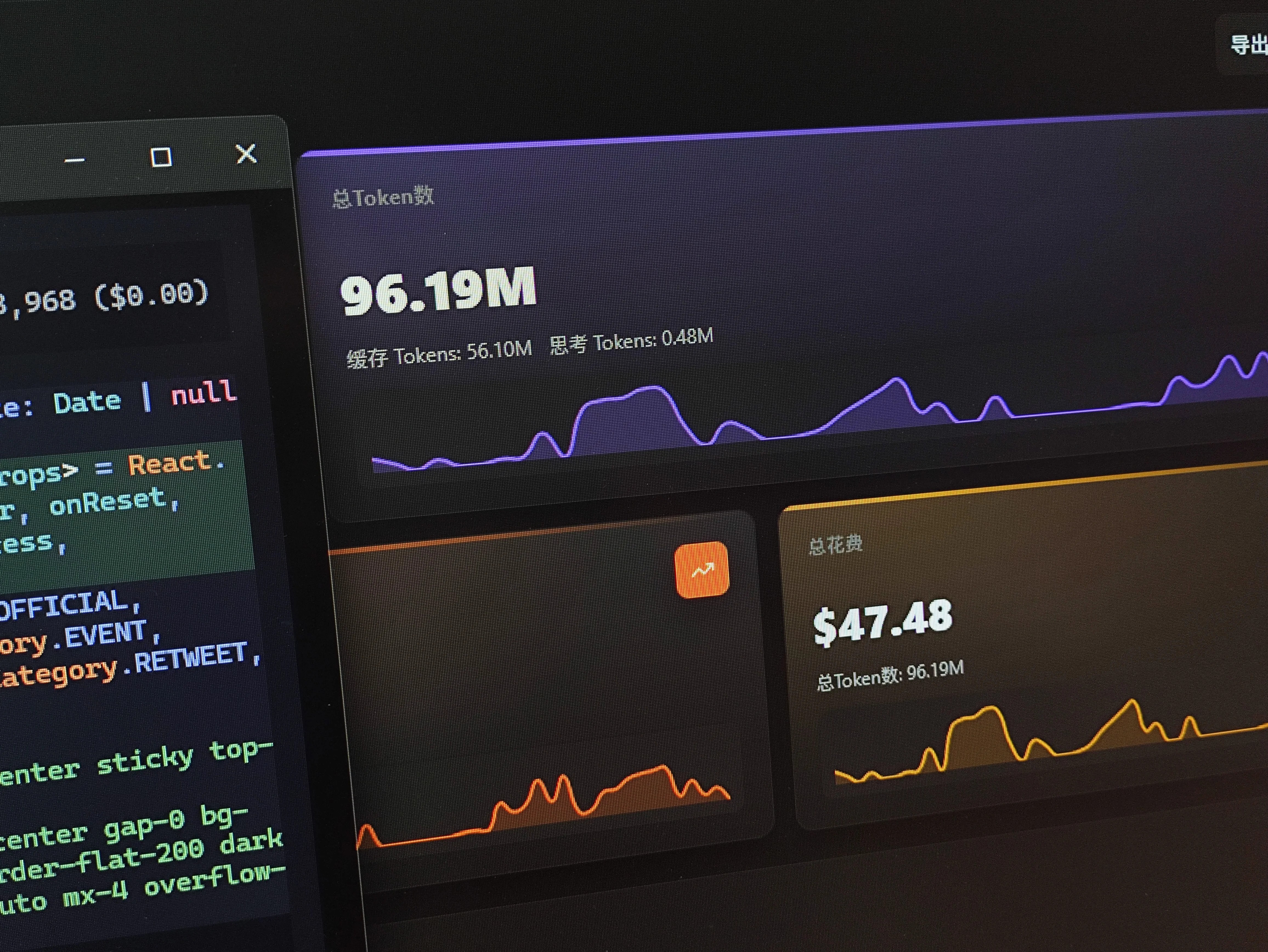
另外因为本身就是兼容多个模型的,所以使用起来也比在CC中使用自定义的模型好了不少。有一天我一下子就用了大概100M的token,想了想确实是有点太恐怖了。